Dans le domaine de l’e-commerce, les solutions de recherche sur site répondent souvent à deux types d’acheteurs distincts : le » chercheur « , qui sait exactement ce qu’il veut, et le » chercheur « , qui navigue pour trouver ce dont il a besoin. Historiquement, l’optimisation pour un type d’acheteur s’est souvent faite au détriment de l’autre.
Cependant, les progrès récents de l’intelligence artificielle, en particulier les modèles de langage, nous permettent d’atteindre un équilibre parfait, répondant aux besoins de chaque consommateur. Ce billet explore l’évolution de la recherche en e-commerce et la façon dont l’e-commerce exploite les technologies de pointe pour améliorer les fonctionnalités de recherche.
Précision et rappel dans la recherche
Les moteurs de recherche du secteur de l’e-commerce mettent généralement l’accent sur la précision ou l’étendue du rappel. Si une marque privilégie la précision, le moteur de recherche n’affichera que les résultats qui correspondent exactement à la requête dans le corpus de produits, souvent au détriment d’un ensemble de résultats plus large. Par exemple, si quelqu’un recherche une « veste en cuir rouge », une recherche axée sur la précision n’affichera aucun résultat qui ne contienne pas la combinaison « rouge », « cuir » et « veste » dans la description.
La recherche précise rencontre également des problèmes avec les requêtes à longue traîne. Si vous cherchez « veste en cuir rouge pour un événement en plein air », vous obtiendrez probablement très peu de résultats (voire aucun). Cela est dû au fait que l’on ne trouve pas de correspondance exacte pour tous les termes du corpus de produits (qui peut être simplement un titre + une courte description d’un produit). Même avec des algorithmes comme la relaxation des requêtes, cela conduit à une dégradation non graduelle de la précision par rapport à l’étendue du rappel.

À l’inverse, si une marque donne la priorité à l’étendue du rappel en utilisant une technologie comme la recherche vectorielle alimentée par l’intégration, vous aurez plus de résultats à afficher, mais il peut y avoir plus de bruit dans l’ensemble de rappel avec des produits non pertinents. Ainsi, pour reprendre l’exemple de la « veste en cuir rouge », vous obtiendrez peut-être des résultats pour des vestes qui ne sont pas rouges, ou qui ne sont pas de la bonne matière, ou même pour des articles qui ne sont pas exactement des vestes mais qui y ressemblent (comme une chemise).
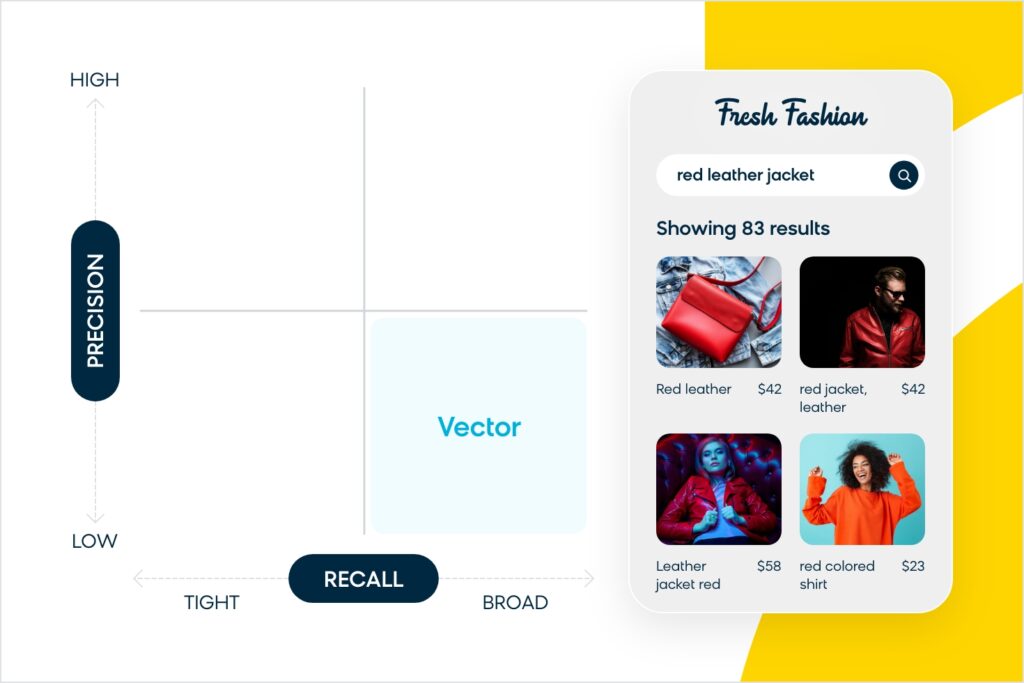
Aucune de ces options de recherche n’est idéale, car elles favorisent fortement un type d’acheteur par rapport à un autre. Le « Saint Graal » des moteurs de recherche est d’exceller à la fois dans la précision et le rappel. Vous devez être précis, mais aussi suffisamment intuitif pour comprendre ce que les gens recherchent, même s’ils ne l’ont pas spécifiquement cherché.
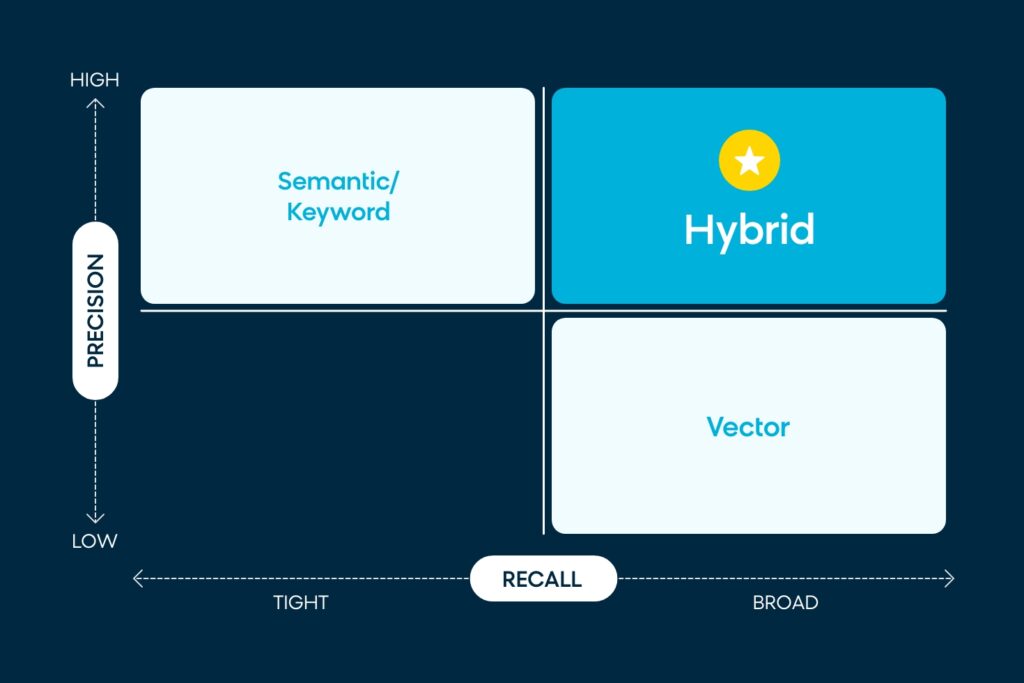
Quel est le classement de Bloomreach ?
Chez Bloomreach, notre moteur de recherche a essayé d’équilibrer cela en combinant les méthodes de précision et de rappel. Nos capacités de compréhension sémantique nous ont permis d’analyser les requêtes de recherche et de fournir des résultats pertinents. Lorsque l’ensemble de rappels était trop faible, nous nous tournions vers des algorithmes tels que la relaxation des requêtes pour afficher davantage de résultats.
Par exemple, pour la requête « veste en cuir rouge », notre recherche sémantique peut décomposer les termes pour comprendre que « rouge » est l’attribut, « cuir » est le matériau et « veste » est l’objet. Il peut également y avoir des règles de synonymie en place, de sorte que « vestes en cuir cramoisi » apparaissent également.
Cependant, lorsque nous nous tournons vers la relaxation des requêtes, les résultats peuvent générer plus de bruit. Cela s’explique par le fait que nous nous sommes appuyés sur des règles heuristiques telles que l’abandon de mots pour correspondre au corpus. Si « veste en cuir rouge » ne produit pas de résultats, par exemple, nous pourrions simplement spécifier que le moteur de recherche supprime « rouge » et affiche « vestes en cuir » à la place.
Cette approche pose un problème : s’il existe un produit similaire (par exemple, une « veste en cuir bordeaux ») qui n’est pas associé à une règle de synonymie, il risque d’apparaître à la page trois des résultats de recherche après relâchement de la requête. Nous savions que nous devions améliorer notre recherche pour la rendre plus sophistiquée, et c’est là que Google Vertex AI et la recherche vectorielle hybride entrent en jeu.
Pourquoi la recherche vectorielle hybride est-elle la solution ?
Grâce à notre partenariat avec Google, nous pouvons désormais exploiter la puissance de leur plateforme Vertex AI et des modèles de langage Gemini pour obtenir le meilleur des deux mondes : un large ensemble de rappels capable de comprendre les requêtes courtes et longues, superposé à notre puissante intelligence sémantique pour obtenir des résultats très précis et pertinents sans avoir recours à des méthodes plus archaïques telles que la relaxation des requêtes. Regardons de plus près comment tout cela fonctionne.
Explication de la recherche vectorielle hybride
Avec un moteur de recherche hybride, les grands modèles de langage (LLM) font le gros du travail, éliminant le besoin de synonymes prédéfinis ou de règles d’assouplissement des requêtes. Au lieu de cela, l’IA utilise des modèles d’intégration et la recherche vectorielle pour effectuer la mise en correspondance de la requête avec le corpus de produits. Le modèle d’intégration est un réseau neuronal qui a une compréhension inhérente des concepts humains, pré-entraîné avec du texte, puis affiné par Bloomreach pour fonctionner dans le domaine des produits. Cela permet de faire correspondre plus précisément les requêtes au niveau du concept humain avec les produits.
Pour revenir à notre exemple de « veste en cuir rouge », les LLM ont une compréhension innée de cette requête en tant que concept, reconnaissant que « rouge » et « bordeaux » sont similaires, alors que « veste » et « canapé » ne le sont pas. Les attributs ne sont plus binaires (par exemple, le mot « rouge » figure-t-il dans le nom/la description ou non ?) – le réseau neuronal attribue un score entre 0 et 1 pour déterminer la proximité d’une correspondance.
Cela signifie que « veste en cuir rouge » et « veste en cuir bordeaux » peuvent avoir un score de 0,98, alors qu’un « canapé en cuir rouge » aura un score de 0,5, qui sera inférieur au seuil de notre ensemble de rappel, et donc éliminé de l’ensemble de rappel.
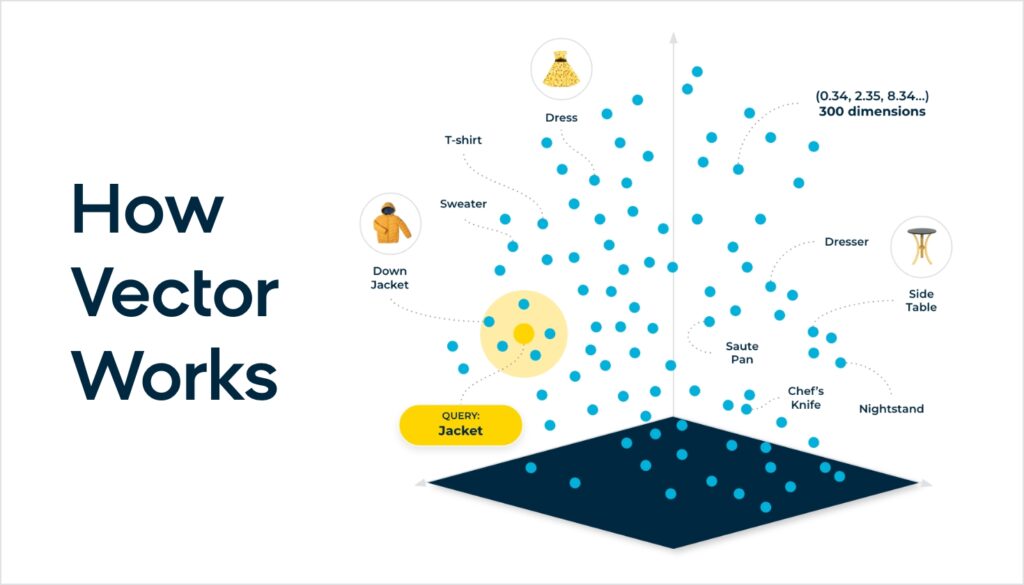
Si l’on va plus loin, la différence essentielle dans l’intégration de modèles d’IA linguistique est qu’il n’est pas nécessaire de recourir à un NLP basé sur un algorithme heuristique. En un sens, il n’y a pas d’instructions « si » dans l’algorithme. L’intégration est générée par le réseau neuronal au moyen d’un ensemble d’opérations mathématiques matricielles. Chaque aspect d’une requête de recherche est cartographié dans un espace à haute dimension, en considérant chaque mot par rapport à tous les autres mots et en attribuant une probabilité sous la forme d’un vecteur d’intégration. L’intégration résultante contient la représentation numérique du concept de « veste en cuir rouge ».
Le résultat final est que nous avons débloqué des possibilités sans limites pour délivrer de la pertinence. Ceci est particulièrement utile pour les requêtes à longue traîne – par exemple, avec une recherche de « veste en cuir rouge adaptée à l’automne », l’IA peut intrinsèquement mieux comprendre cette requête et la faire correspondre avec le produit approprié dans le corpus du catalogue, qui peut être une veste en cuir rouge plus légère ou plus fine, mais qui ne mentionne pas le temps d’automne dans la description.
Nous reconnaissons également que les modèles d’intégration et l’algorithme de mise en correspondance utilisant la similarité cosinus ont des limites. La dimensionnalité de l’intégration est un type de compression qui prend des concepts et les compresse en 768 ou 1024 ou un ensemble plus élevé de dimensions vectorielles, ce qui peut introduire des erreurs de précision lors de l’utilisation des scores de similarité cosinus. Le vecteur hybride est une méthode qui utilise la correspondance lexicale classique comme signal de notation supplémentaire en combinaison avec les modèles vectoriels et d’intégration, ce qui permet d’atteindre le Saint-Graal de la précision et de l’étendue du rappel.
L’avantage Bloomreach
Il est important de noter que, bien que nous ne soyons pas les seuls à tirer parti de la technologie de Google, Bloomreach dispose d’un avantage certain par rapport à tous ceux qui utilisent ces modèles. En effet, nous avons affiné les modèles avec plus de 15 ans de données spécifiques à l’e-commerce, avec en point d’orgue le lancement de Loomi Search+.

Lorsque les moteurs de recherche ne s’appuient que sur des modèles d’intégration classiques, les paramètres du modèle peuvent être optimisés pour la recherche de documents génériques. Ainsi, l’IA peut comprendre toutes les différences entre « airplanes » et « jets », mais peut ne pas comprendre les similitudes entre des produits tels que « red leather jacket » vs « burgundy leather jacket ».
Loomi Search+ puise dans nos données e-commerce étendues, et nous avons affiné nos LLM pour comprendre plus précisément un large éventail de produits de commerce. Nous avons combiné ces modèles affinés avec la recherche lexicale classique comme un signal supplémentaire pour nous donner la meilleure précision. Nous ne nous contentons pas de proposer une recherche vectorielle hybride, nous proposons une recherche vectorielle hybride hautement optimisée pour les marques de commerce et leurs clients.
Je suis très enthousiaste à l’idée de voir le « Saint Graal » de la recherche se concrétiser. Mais ce n’est pas la seule chose passionnante sur laquelle nous travaillons – ne manquez pas de consulter toutes les innovations de Bloomreach Discovery basées sur l’IA.