In the realm of ecommerce, site search solutions often cater to two distinct types of shoppers: the “searcher,” who knows exactly what they want, and the “seeker,” who browses to find what they need. Historically, optimizing for one type of shopper has often come at the expense of the other.
However, recent advancements in artificial intelligence, in particular language models, are enabling us to strike a perfect balance, meeting the needs of every consumer. This post explores the evolution of ecommerce search and how Bloomreach is leveraging cutting-edge technology to enhance search functionality.
Precision vs. Recall in Search
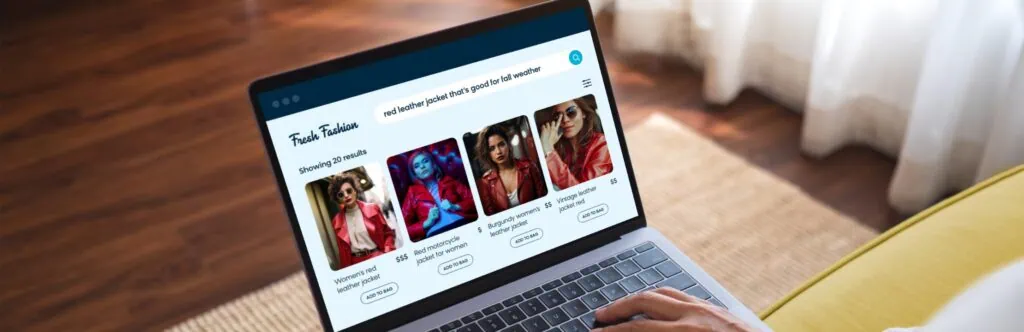
Ecommerce search engines typically focus on either precision or recall breadth. If a brand prioritizes precision, the search engine will only show results that exactly match the search query in the product corpus, often at the expense of a larger results set. For instance, if someone searches for a “red leather jacket,” a precision-focused search won’t show any results that don’t include the combination of “red,” “leather,” and “jacket” in the description.
Precise search also encounters issues with long-tail queries. If you search for “red leather jacket for an outdoor event,” you’ll likely return very few (or even zero) results. This is due to not finding exact matches for all the terms in the product corpus (which can be just a title + a short description of a product). Even with algorithms like query relaxation, this leads to a non-graceful degradation of precision versus recall breadth.

Conversely, if a brand prioritizes recall breadth using technology like embedding-powered vector search, you’ll have more results to show, but there may be more noise in the recall set with irrelevant products. So, with the same “red leather jacket” example, this may return results for jackets that are not red, or not the right material, or even items that aren’t exactly jackets but similar to jackets (like a shirt).
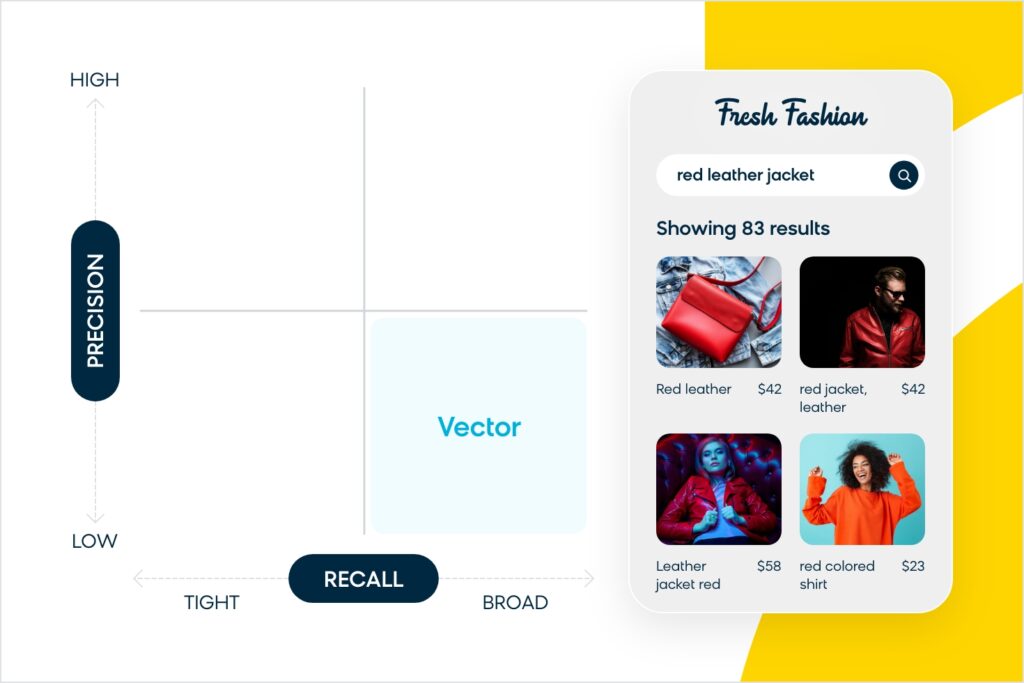
Neither of these search options is ideal, as they each heavily favor one type of shopper over another. Instead, the “holy grail” for search engines is to excel in both precision and recall. You need to be precise but also intuitive enough to understand what people are looking for, even if they didn’t specifically search for it.
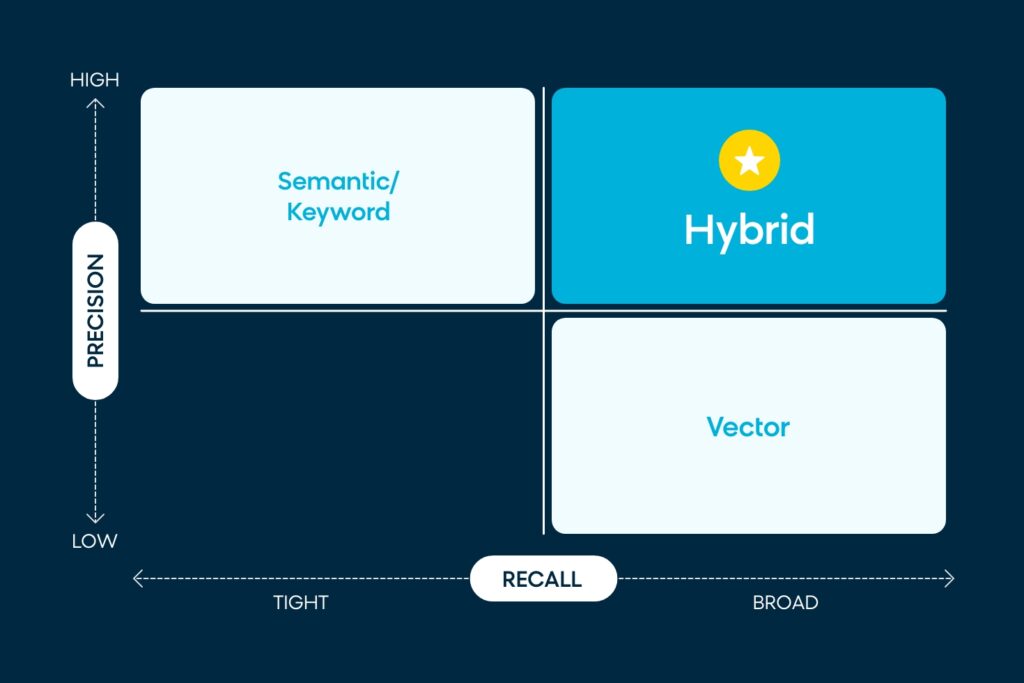
Where Does Bloomreach Rank?
At Bloomreach, our search engine has tried to balance this through a combination of precision and recall methods. Our semantic understanding capabilities allowed us to parse search queries and deliver relevant results. When the recall set was too low, we would turn to algorithms like query relaxation to show more results.
For example, with the “red leather jacket” query, our semantic search can break down the terms to understand that “red” is the attribute, “leather” is the material, and “jacket” is the object. There may also be synonym rules in place, so that “crimson leather jackets” show up as well.
However, once we turn to query relaxation, the results may generate more noise. This is because we’ve relied on heuristic rules like dropping words to match with the corpus. If “red leather jacket” doesn’t produce results, for example, we would simply specify that the search engine drop “red” and show “leather jackets” instead.
One problem with this approach is that if there were a similar product (e.g., a “burgundy leather jacket”) that didn’t have a synonym rule attached to it, it might end up appearing on page three of the search results after query relaxation. We knew we needed to improve our search to be more sophisticated, which is where Google Vertex AI and hybrid vector search come into play.
Why Hybrid Vector Search Is the Answer
Thanks to our partnership with Google, we can now leverage the power of their Vertex AI platform and Gemini language models to achieve the best of both worlds: a broad recall set capable of understanding both short and long queries, layered on top of our powerful semantic intelligence for highly precise and relevant results without relying on more archaic methods like query relaxation. Let’s take a closer look at how it all works.
Hybrid Vector Search, Explained
With a hybrid search engine, large language models (LLMs) do the heavy lifting, eliminating the need for predefined synonyms or query relaxation rules. Instead, the AI uses embedding models and vector search to perform similarity matching of the query with the product corpus. The embedding model is a neural network that has an inherent understanding of human concepts, pre-trained with text, and then fine-tuned by Bloomreach to work in the product domain. This more accurately matches queries at a human concept level with the products.
Returning to our “red leather jacket” example, the LLMs have an innate understanding of this query as a concept, recognizing that “red” and “burgundy” are similar, while “jacket” and “couch” are not. Attributes are no longer binary (e.g., is “red” in the name/description or is it not?) — the neural network assigns a score between 0 and 1 to determine the closeness of a match.
This means “red leather jacket” and “burgundy leather jacket” might have a 0.98 match score, while a “red leather couch” will have a 0.5 score, which would be below the threshold of our recall set, and thus eliminated from the recall set.
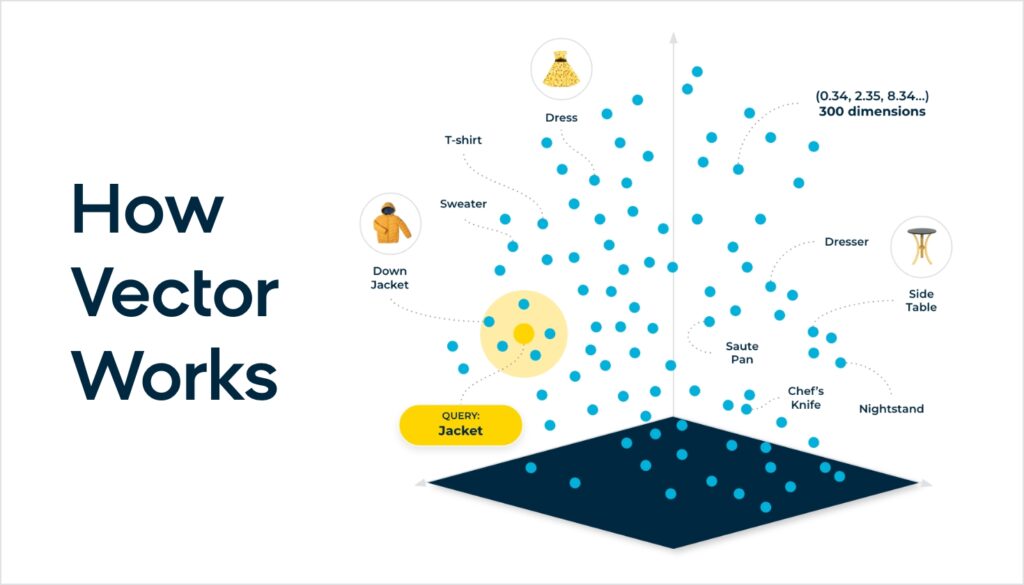
Diving deeper, the key differentiator in embedding language AI models is not needing heuristic algorithm-based NLP. In a sense, there are no “if” statements in the algorithm. The embedding is generated through the neural network via a set of matrix math operations. Each aspect of a search query is mapped out in a high-dimensional space, considering each word in relation to every other word and assigning a probability in the form of a vector embedding. The resulting embedding contains the numerical representation of the concept of “red leather jacket.”
The end result is that we have unlocked limitless possibilities for delivering relevancy. This is especially useful for long-tail queries — for example, with a search of “red leather jacket that’s good for fall weather,” the AI can inherently understand this query better and match it with the proper product in the catalog corpus, which may be a red leather jacket that is lighter or thinner but doesn’t mention anything about fall weather in the description.
We also recognize that embedding models and the algorithm for matching using cosine similarity have limitations. The embedding dimensionality is a type of compression that takes concepts and compresses them into 768 or 1024 or some higher set of vector dimensions, which may introduce precision errors when using cosine similarity scores. Hybrid vector is a method that utilizes classical lexical matching as an additional scoring signal in combination with vector and embedding models achieving the holy grail of both precision and recall breadth.
The Bloomreach Advantage
It’s important to note that while we’re not the only ones leveraging Google’s technology, we have a distinct advantage at Bloomreach over anyone else using these models. That’s because we’ve been fine-tuning the models with over 15 years’ worth of ecommerce-specific data, culminating in the launch of Loomi Search+.

When search engines only rely on vanilla embedding models, the model parameters might be optimized for generic document search. So, the AI might understand all the differences between “airplanes” and “jets,” but may not understand the similarities between products like “red leather jacket” vs. “burgundy leather jacket.”
Loomi Search+ taps into our extensive ecommerce data, and we’ve fine-tuned our LLMs to more accurately understand a wide range of commerce products. We have combined these fine-tuned models with classic lexical search as an added signal to give us the best precision. We’re not just delivering hybrid vector search — we’re delivering hybrid vector search that’s highly optimized for commerce brands and their customers.
I’m very excited to see the “holy grail” of search come to fruition. But this isn’t the only exciting thing we’re working on — be sure to check out all of Bloomreach Discovery’s AI-driven innovations.