The AI models powering your ecommerce search and personalization are only as good as the data they learn from.
When a shopper types “waterproof jacket for New York winters under $200,” the search engine behind the results needs more than keyword matching. It needs context: what that shopper clicked last time, what similar shoppers purchased, and what “under $200” means for this specific product catalog. The data powering that understanding matters more than most ecommerce teams realize.
A growing number of vendors are turning to synthetic data (artificially generated by AI models) to train their search and personalization algorithms. The appeal is obvious: instant scale, no cold-start problem, no dependency on collecting real customer behavior. But research from Columbia University and others is revealing a significant catch. Synthetic data produces a smoothed-out, homogenized version of customer behavior that misses the messy, diverse reality of how people actually shop.
Here’s what the real vs. synthetic data debate means for your ecommerce search, and what a better approach looks like.
Want the full deep dive? Watch the on-demand webinar , where Jordan Roper, GM of Discovery & Search at Bloomreach, walks through the research, live product examples, and what’s coming next.
The Stakes: Why Search Data Quality Is a Revenue Problem
The revenue case for getting ecommerce search personalization right is well established. McKinsey research found that personalization leaders generate 40% more revenue from those activities than average players, with top performers seeing up to 25% revenue lift.
For site search specifically, the gap is even wider. Shoppers who use site search convert at rates 2-6x higher than those who browse. Amazon’s conversion rate jumps to 12% when visitors search rather than browse.
What’s less established is how much the type of data behind those algorithms matters. Most ecommerce teams optimize their search UX (autocomplete, filters, zero-result pages) without questioning whether the underlying training data accurately represents how their customers actually behave. That’s the question at the center of the real vs. synthetic data debate.
The Data That Powers Personalized Search
Most ecommerce search platforms start with clickstream data: what shoppers searched, what they clicked, what they added to cart, what they bought. This is the foundation, and it works. Clickstream signals tell you which products convert for which queries, and that’s genuinely valuable for ranking.
The problem is that clickstream data alone misses a lot.
Consider what a richer first-party data profile includes:
- Behavioral characteristics beyond clicks: scroll depth, dwell time, return frequency, cross-session patterns
- Customer context: loyalty status, lifetime value tier, geographic signals, device preferences
- Conversational data: what shoppers ask your chat agents, how they describe what they want in natural language
- Cross-channel signals: email engagement patterns, SMS responses, app behavior that reveal preferences the search box never captures
When all of these signals feed into your personalization engine, the search experience changes in measurable ways. A returning high-value customer searching “jacket” sees different results than a first-time visitor searching the same term, because the system understands their context beyond the query itself.
The question the market is debating right now is whether you actually need all that real data, or whether AI-generated synthetic data can fill the same role.

The Synthetic Data Shortcut (and Why It Falls Short)
Synthetic data has legitimate appeal. If you’re launching a new site, entering a new market, or adding a product category with no behavioral history, generating artificial training data can solve the cold-start problem quickly. Several ecommerce vendors and martech platforms have leaned into synthetic data to bootstrap their algorithms.
But the research is catching up with the hype.
What Columbia University Found
A NeurIPS 2025 study from Columbia University, “LLM-Generated Persona is a Promise with a Catch,” tested approximately one million synthetic personas across six open-source large language models. The researchers evaluated how well LLM-generated personas could simulate real human behavior across more than 500 questions.
Their findings were striking. When given freedom to generate persona attributes, the simulated results progressively deviated from real-world outcomes. The synthetic personas exhibited a strong “positivity bias,” producing profiles that were systematically more successful, well-adjusted, and socially conscious than real population distributions.
For ecommerce, the implication is direct: if your synthetic personas don’t capture the full range of how real shoppers behave, your personalization algorithms learn from a distorted picture.
The Bunching Problem
A separate analysis from Nielsen Norman Group synthesized three academic studies on synthetic users in product evaluation scenarios. The findings reinforced Columbia’s conclusions. Synthetic users captured directional trends but missed the magnitude and variability of real human responses. Standard deviations were consistently lower, meaning synthetic behavior clustered around the middle of the bell curve.
Think about what that means for ecommerce search. Your real shoppers include impulse buyers, methodical researchers, price-sensitive bargain hunters, brand-loyal repeat customers, and everything in between. Each of these behaviors should influence what “relevant” means for a given query. Synthetic data smooths all of that into a generic median, training your algorithms on a version of customer behavior that overrepresents the average and underrepresents the edges where real personalization creates value.
Where Synthetic Data Still Works
This isn’t a case for abandoning synthetic data entirely. It has clear utility for:
- Cold-start scenarios: new product launches, new market entry, new categories with zero behavioral history
- Offline model training: bootstrapping initial algorithm development before live data is available
- Catalog enrichment: generating product metadata, descriptions, and attributes at scale
The risk comes when synthetic data moves from supplement to foundation. If it becomes the baseline of your search ranking or personalization models, the homogenized behavior it represents will limit the ceiling of what those models can achieve.

Smart Amplification: Combining Real Data with AI
If the answer isn’t pure synthetic data, and collecting enough real behavioral data takes time, what’s the practical path forward?
The approach we’ve invested in at Bloomreach is what we call smart amplification: using AI to extend the reach and impact of real first-party behavioral data, rather than replacing it with synthetic substitutes. We’ve built Loomi AI around this principle — our agentic platform ingests first-party data across customer profiles, product catalogs, marketing interactions, and real-time behavioral signals, then processes it within milliseconds to influence search ranking, recommendations, and personalization in the same session.
Here’s a concrete example. Our performance sharing capability analyzes all queries in your system and identifies semantically similar searches. If “wall art” and “wall print” are similar queries but “wall art” has significantly more traffic and conversion data, performance sharing distributes the ranking learnings from the high-traffic query to the low-traffic tail query. The result: better search results for long-tail queries, grounded in real customer behavior rather than synthetic approximations.
This matters because long-tail queries make up the majority of searches on most ecommerce sites, and they’re exactly where cold-start and data sparsity problems hit hardest. Instead of filling that gap with generated behavior, we amplify what real shoppers have already told us through their actions.
Customers using performance sharing have seen RPV improvements ranging from 1.5% to 7%, depending on catalog size and query distribution. These are bottom-line results from real behavioral data doing more work across the site.
Real Results from Behavioral Data-Driven Search
The argument for first-party data over synthetic data isn’t theoretical. It shows up in the metrics.
The Vitamin Shoppe implemented Bloomreach’s AI-powered search and saw a 7.73% increase in search add-to-cart rate, a 6.51% lift in search AOV, and a 5.69% boost in RPV. These gains came from search algorithms trained on real shopper behavior across a complex catalog with thousands of supplement products, each with nuanced attributes that matter to health-conscious buyers. Synthetic data would have smoothed over those nuances.
Canadian Tire achieved a 20%+ increase in conversions across multiple brands (Atmosphere, Mark’s, SportChek) by letting Bloomreach’s behavioral models learn from cross-brand shopping patterns. Each brand’s search experience improved because it could draw on real customer intent signals from the broader network.
Wolseley, a B2B industrial distributor, saw £24.17 additional revenue per visitor after implementing Bloomreach search, along with an 18-point increase in add-to-cart rates and a 9.6-point jump in search conversion. B2B search is particularly sensitive to data quality because queries involve part numbers, technical specifications, and compatibility requirements that synthetic data would struggle to model accurately.

The Future of Ecommerce Search Personalization
The data question becomes even more critical as search evolves beyond the traditional text box.
Conversational Search Changes the Data Equation
As ecommerce search becomes more conversational, shoppers are expressing intent in ways that structured queries never captured. “I need a gift for my dad who’s into woodworking but already has every tool” tells you something that no amount of synthetic training data could generate. Those natural language interactions create a new layer of first-party behavioral data that enriches every subsequent interaction.
We’ve seen this play out with our conversational shopping agent. Customers who interact with conversational search show higher AOV and add-to-cart rates because the system captures richer intent signals and responds in real time.
Agentic Commerce Raises the Stakes
The emergence of AI agents acting on behalf of shoppers (through tools like ChatGPT, custom agents, or voice interfaces) creates a new channel where the quality of your product data and behavioral intelligence determines whether your products surface at all. When an AI agent queries your catalog on behalf of a shopper, it expects precise, contextually relevant results. This is an area where the depth and accuracy of real behavioral data creates a competitive moat that synthetic substitutes can’t replicate.
Put Your First-Party Data to Work
If your ecommerce search is still running on basic keyword matching or vendor-provided models trained on synthetic data, the gap between your current performance and what’s achievable is likely larger than you think.
Bloomreach’s ecommerce search is built on a real-time behavioral data backbone powered by Loomi AI. We capture the widest breadth of first-party signals from your customers and amplify their impact across search, recommendations, and personalization, without relying on synthetic shortcuts.
See how Loomi AI delivers search personalization grounded in real customer behavior.
Frequently Asked Questions About Synthetic Data
Why does first-party data matter for ecommerce site search?
First-party data captures how your actual customers behave: what they search, click, add to cart, and buy. Search algorithms trained on this data learn patterns that reflect real purchase intent, price sensitivity, and product preferences specific to your catalog and audience. Synthetic or third-party data can approximate these patterns but lacks the nuance of real customer behavior, particularly for long-tail queries and niche product categories.
What is the difference between real and synthetic data for AI?
Real data comes from actual user interactions (clicks, purchases, browsing behavior, conversations). Synthetic data is artificially generated by AI models to simulate these interactions. Research shows shows that synthetic data tends to oversimplify human behavior, clustering around averages and missing the edge cases that make personalization effective.
Can synthetic data replace real customer data for ecommerce personalization?
Not as a foundation. Synthetic data is useful for cold-start scenarios (new products, new markets) and offline model training, but when used as the primary input for search ranking and personalization, it produces homogenized results. Real behavioral data captures the messy, diverse ways people actually shop, including impulse purchases, brand loyalty patterns, and context-dependent preferences that synthetic models systematically underrepresent.
How does behavioral data improve ecommerce search results?
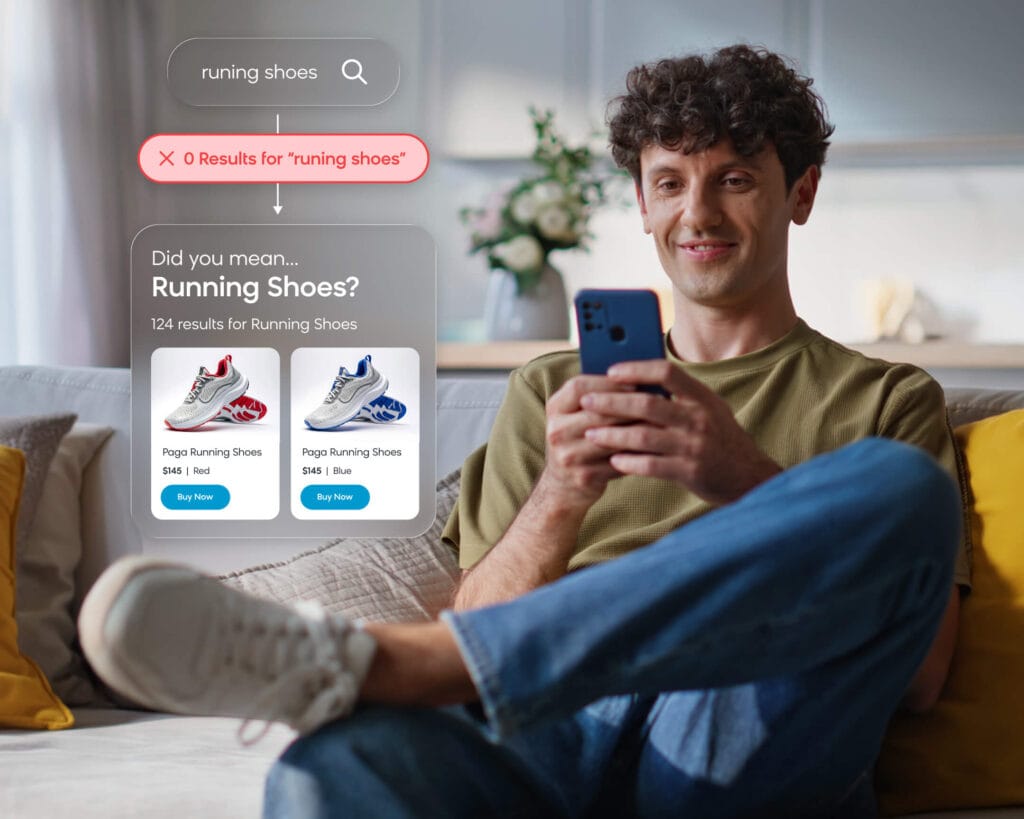
Behavioral data helps search engines understand which products are relevant for which queries, in context. When a query like “running shoes” generates clicks and purchases on specific products, those signals teach the ranking algorithm what “relevant” means for that query on your site. Behavioral data also enables 1:1 personalization, where search results adapt to individual shoppers based on their history, preferences, and real-time session behavior.
What data do you need for AI-powered ecommerce search?
At minimum, clickstream data (searches, clicks, add-to-carts, purchases) provides the foundation for learning-to-rank models. For more advanced personalization, you need broader first-party signals: customer profiles, loyalty data, cross-channel engagement, conversational interactions, and product catalog data. The more behavioral context your search engine has access to, the better it can personalize results for individual shoppers.
What are the leading trends in ecommerce search personalization?
The biggest shifts include the move from keyword-based to AI-powered semantic search, the rise of conversational shopping interfaces, and the emergence of agentic commerce where AI agents shop on behalf of consumers. Underpinning all of these is a growing focus on first-party data quality, as the sophistication of AI models makes the data they’re trained on even more consequential.