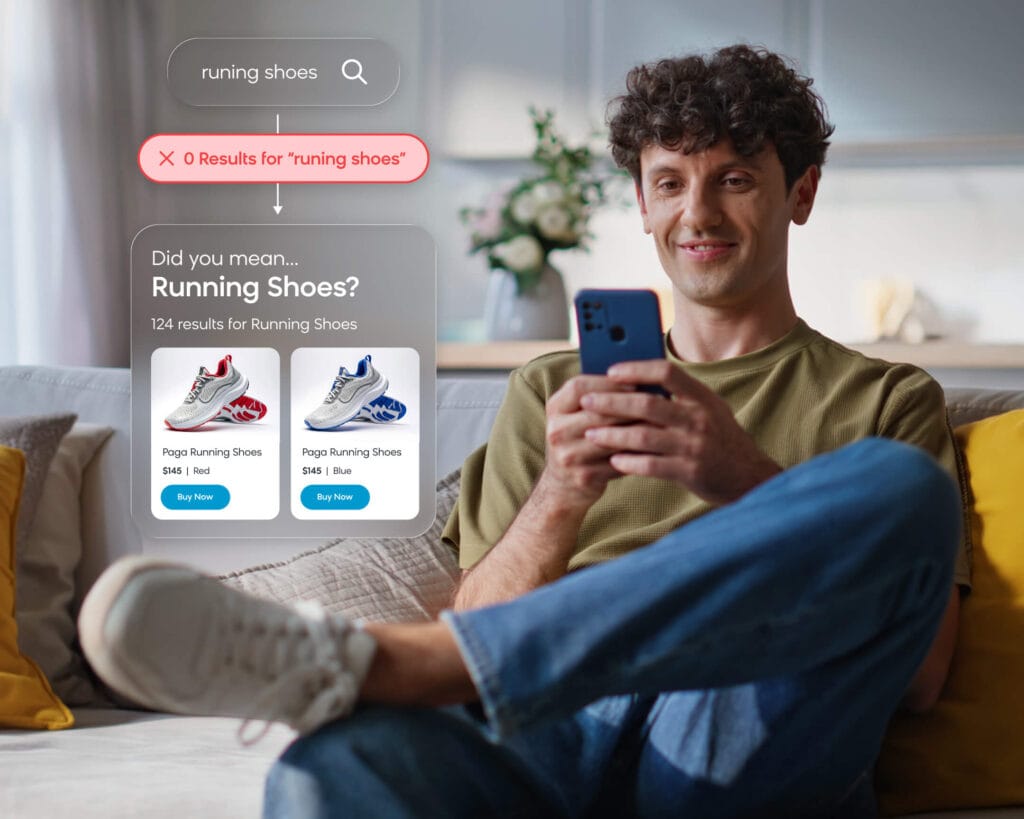
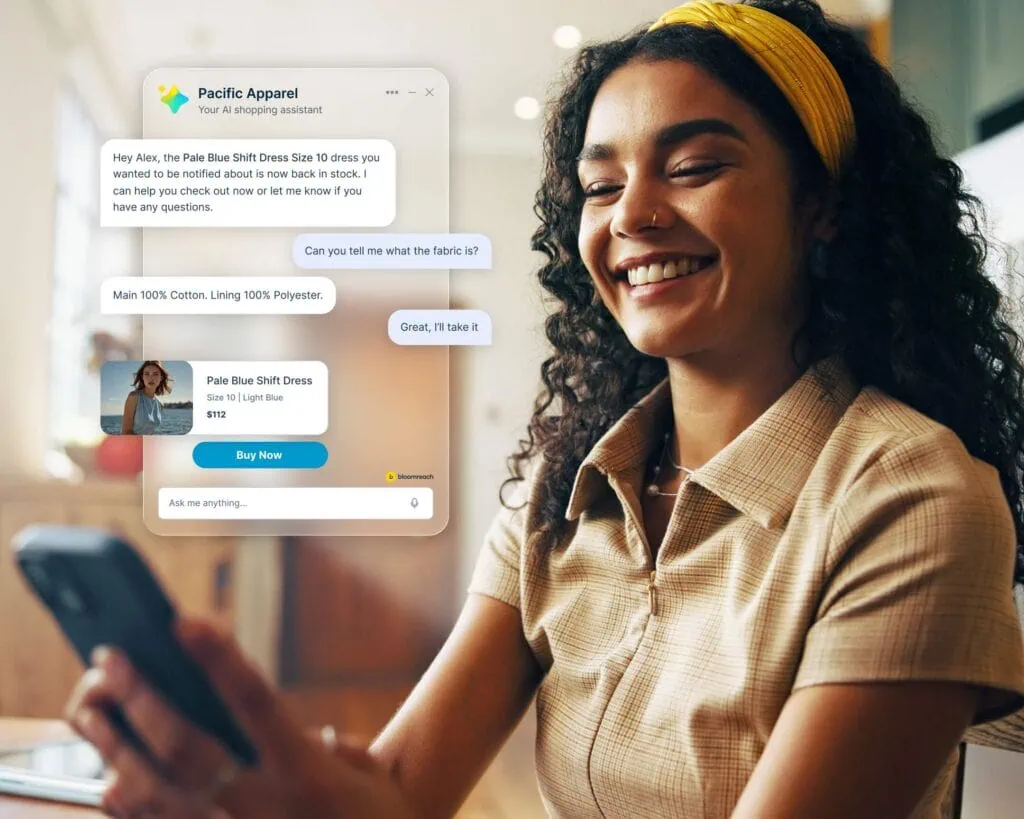
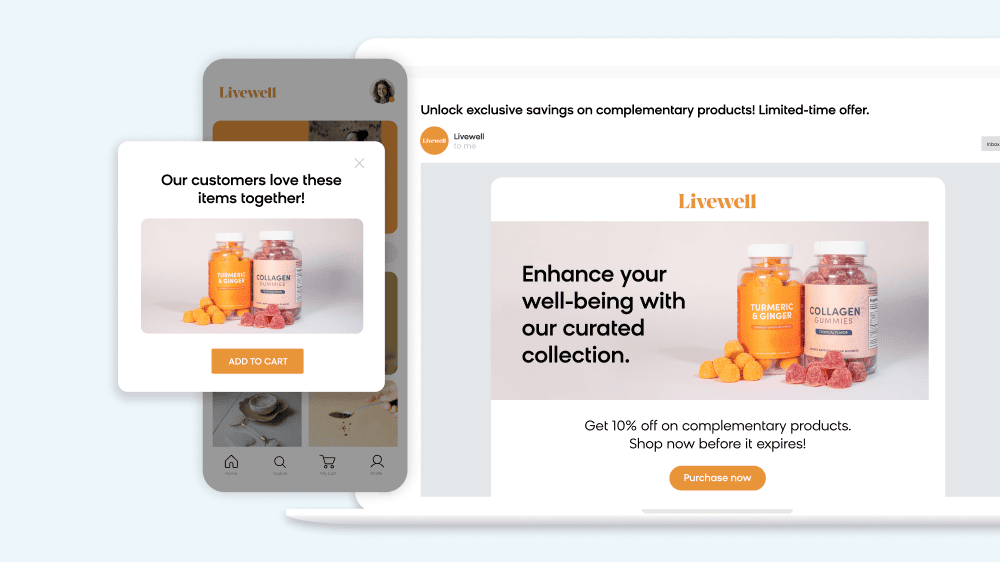
At Bloomreach, we’ve extensively discussed the role of large language models (LLMs) in powering Loomi AI. These models are integral to our solutions, enabling us to process vast amounts of data and create hyper-personalized experiences through deep learning. However, LLMs can be resource-intensive, with high latency and significant costs.
To address these challenges, we are exploring the potential of small language models (SLMs). In this post, I’ll dive into the emergence of SLMs and how we’ve been looking into using them for our solutions.
Why Small Language Models (SLMs)?
SLMs offer a compelling alternative by enhancing performance and reducing costs. They can deliver much of the performance and quality associated with LLMs but at a lower cost and with reduced latency.
This advancement is due to industry innovations and methodologies that improve model quality through various architectural and training refinements, including:
- Knowledge distillation — Training a smaller “student” model to replicate the behavior of a larger “teacher” model
- Fine-tuning — Using high-quality and domain-specific data sets to fine-tune small models and enhance their performance on specific tasks
- Quantization — Reducing the precision of the model’s weight precision (i.e., 16-bit to 4-bit) and activations to greatly improve performance and reduce cost
- Model pruning and sparsity — Reducing a model’s breadth of knowledge and quality of output (by removing redundant or less significant weights) to improve performance and cost-optimization
- Mixture of Experts (MoE) — Using multiple small specialized models (experts) that activate a smaller subset of the network to reduce the total parameter count
- Agent architecture — Combining smaller neural networks with symbolic reasoning components to handle complex reasoning tasks
- Prompt tuning — Using advanced data encoding techniques to enhance result quality while reducing network parameters
How We’re Approaching SLMs at Bloomreach
Currently, we are selectively applying SLMs to specific use cases within our products. For instance, we use knowledge distillation to develop smaller models for search attribute extraction and fine-tune them with commerce-specific data. SLMs are also integrated into our agent architecture for Bloomreach Clarity and the next iteration of Loomi AI within Bloomreach Engagement.
Our development process typically begins with prototyping using LLMs. We analyze usage patterns and input prompts, which is feasible given our focus on specific commerce verticals. This allows us to develop benchmarks to assess whether SLMs can meet the same standards. If they do, we implement SLMs to achieve comparable quality.
Our Journey Using SLMs for Bloomreach Clarity
In Bloomreach Clarity, we are transitioning from Gemini 1.5 Pro to Gemini 1.5 Flash. By leveraging Flash’s speed and cost-effectiveness, we can generate more tokens quickly and affordably, simplifying tasks by dividing them into more SLM calls (e.g., pre-search and translation).
For complex tasks, we employ a “chain of thought” strategy, allowing SLMs to generate intermediate results before completing tasks, which helps achieve accurate solutions. This approach, combined with SLMs’ improved latency, enhances quality and accuracy.
Additionally, we instruct our models to generate outputs in JSON format rather than lists. This strategy offers two key benefits:
- It provides reliable, parsable JSON outputs in the correct format
- It ensures a higher-quality response — by defining a JSON structure, you can name JSON keys, which helps the model in a way that’s similar to the chain of thought strategy
As we continue to explore SLMs, we are consistently finding ways to optimize costs and performance while maintaining quality across our products. While we are considering SLMs for all our offerings, we invite you to check out Clarity to witness the effectiveness of SLMs firsthand.