The latest technological advancements in generative AI have led to a boom in improving customer ecommerce experience by delivering the right products from search results and enabling conversational product discovery. This is where Bloomreach Clarity makes a big impact on brands. Our AI conversational shopping agent can deliver conversational experiences that convert across a brand’s entire site.
To maximize the use of these foundational technologies, Bloomreach has partnered with NVIDIA to utilize its leading-edge models and software frameworks to optimize and customize these experiences. In this post, I will take a closer look at how both Bloomreach Clarity and Discovery make use of NVIDIA models and frameworks to enable highly accurate, personalized conversations.
Delivering a Conversational Experience
To ground this discussion, we must first understand what conversational discovery means in the context of ecommerce. When we say “conversational,” the first thing many users will think of is a chatbot. However, in ecommerce specifically, users also typically associate chatbots with customer support, which then turns them away from wanting to interact with one.
To address this, we knew we had to embed conversations in new ways across the on-site experience:
- Behaviorally triggered conversations. Instead of having Clarity pop up in a chat window too early (and then getting ignored), we can set triggers so that Clarity doesn’t engage shoppers until the right time. For example, if someone searches for “jacket” and views at least two pages of results, then Clarity could pop up and ask if they need assistance.
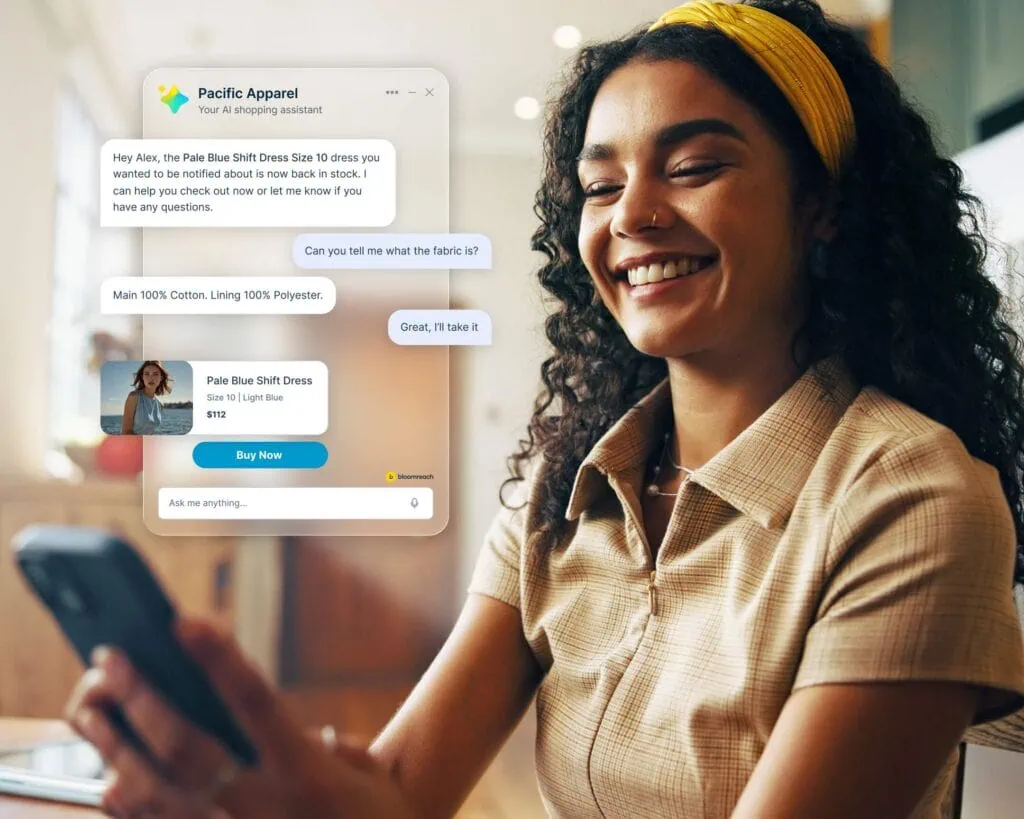
- Conversation starters. We can surface conversations in the form of clickable buttons with relevant questions as people shop. These buttons can appear on category pages, product listing pages, the checkout page, and more. For example, someone looking at a specific mattress might see questions like, “How does the cooling gel in this mattress compare to regular memory foam?” or “What is the return policy for this mattress?” Once a user clicks on a question, it’ll start a conversation with Clarity, and they can continue to interact with the shopping agent from there.
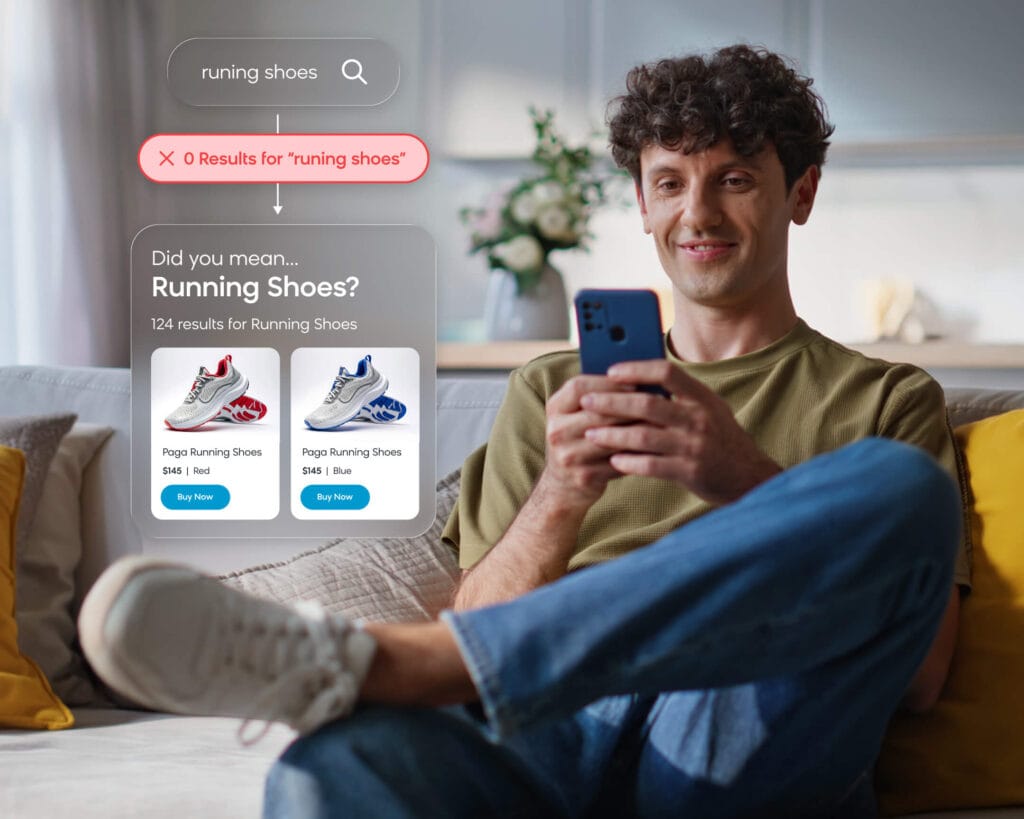
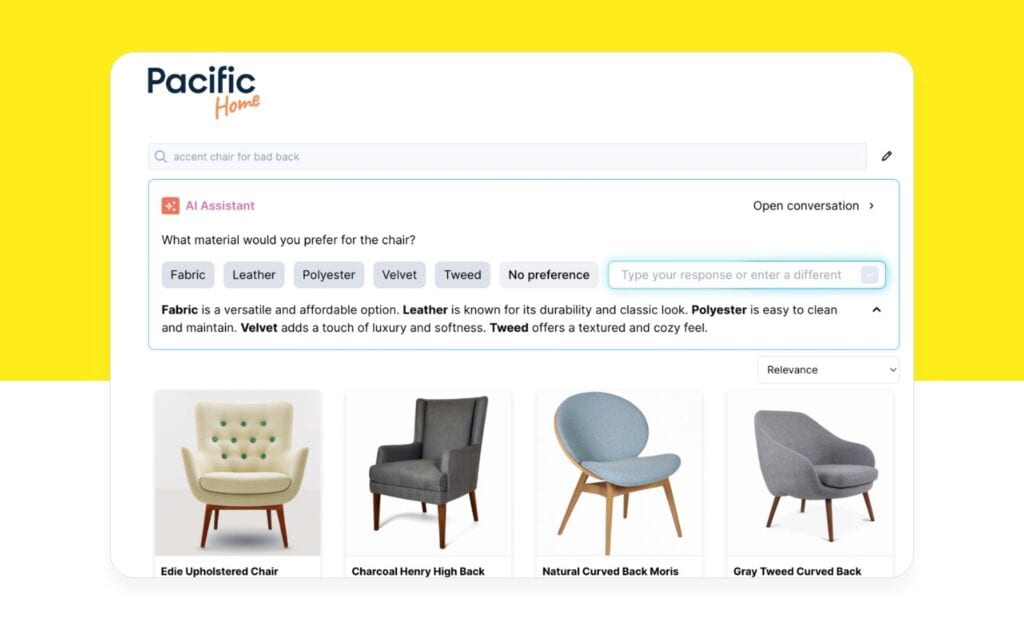
- Search bar. One way to bring conversations to search is through autogenerated questions as they type their search query (which I previously wrote about here). Another option is to show an embedded box on the search results page showing the user’s query and offering help to refine the search. For example, a search for “chair” might result in a box that asks what material the shopper would like.
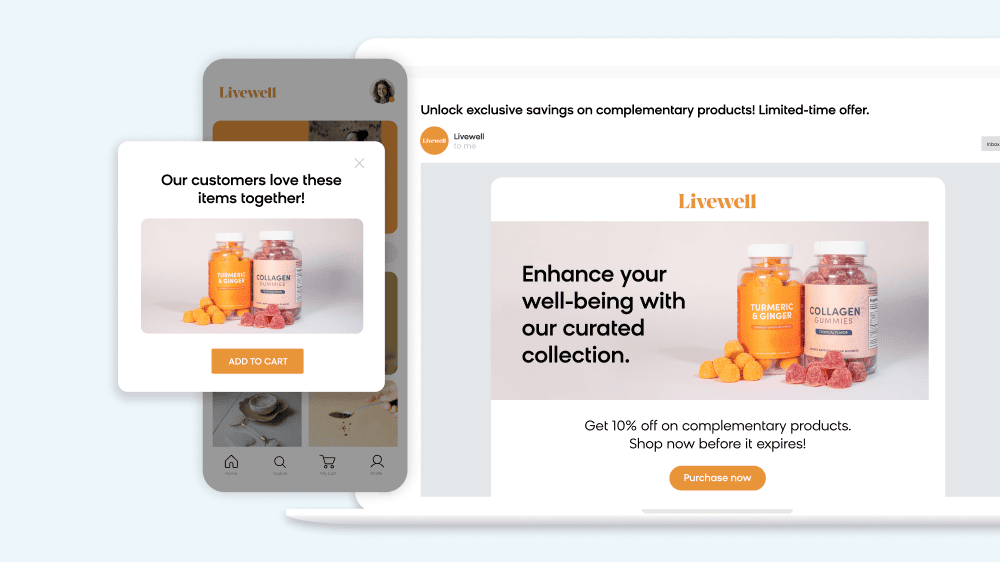
In this way, we can engage customers at just the right moments, whether they’re searching for a specific type of product or just browsing.
A Closer Look at the Clarity Architecture
So, how do we actually deliver these conversational experiences? At its core, Clarity is an agentic, RAG-based platform — more specifically, it’s a limited economy agentic platform with guardrails and latency constraints in place to boost performance.
The architecture consists of a conversation engine and embedded conversational experiences, and it can also utilize Discovery’s hybrid product search engine.
Unlike a traditional search query, which is a one-off experience (i.e., you search for a query and get results), conversational shopping is more of a journey. To that end, we use pre-search, search, and post-search LLM calls to ensure Clarity is delivering value throughout the entire conversation.
We have found that a bottleneck for conversation quality is catalog quality. Many catalogs were designed for website navigation vs. a conversational experience. To clear that bottleneck, we will also use LLMs to generate our own taxonomy and attributes that work better for conversational purposes.
This is where we have deployed NVIDIA’s NIM-hosted Llama models to enable cheaper, faster generative AI calls that augment the product catalog with information that helps the quality of the conversation and search.

Balancing Precision and Recall
We use a mix of embedding models for Clarity, with one of the more effective ones being an open-source arctic-embed model running on NVIDIA NeMo Retriever Embedding Microservice (NREM). This model features state-of-the-art text embedding, which means better natural language processing and understanding capabilities. Additionally, the model is optimized for fine-tuning and customizations so we can further improve on the performance for our use cases, and most importantly, features a lower latency (average of 12ms) for a faster search experience.
To fine-tune our models, we classify queries as either a positive document (relevant) or a negative document (irrelevant). Within these documents, we train using “hard negatives” (high similarity to the query) and “soft negatives” (low similarity to the query).
One of our key learnings was that using more than two hard negatives during training could lead to degradation in understanding. To solve for this, we started using one hard negative and six soft negatives as part of the dataset, allowing for significant improvement on F-scores and relevancy.
Further Improving Accuracy
The contrastive loss function is a standard procedure for bringing positive pairs closer and pushing negative pairs away. However, we modified the contrastive loss function so that it additionally pushes away negative products and positive products from other queries, which greatly improves accuracy.
With these modifications, we saw no change in Vertex AI, but saw substantial improvements in the open-source models. In the NVIDIA-powered arctic-embed, the improved contrastive loss function led to a 13-point gain in precision and a 6-point gain in coverage compared to the base model, while gte-large saw an 8-point gain in precision.
By prioritizing precision (with f0.5, meaning precision was considered twice as important as coverage), arctic-embed saw similar gains — 13 points in precision and 8 points in coverage — while gte-large saw a 4-point gain in precision and a 5-point gain in coverage.
To put this into context, let’s look at a sample search. For the search query “Cuisinart toaster,” the base open-source arctic-embed model eventually ran out of Cuisinart-brand toasters to show and opted to show other Cuisinart products (that had nothing to do with toasters). On the other hand, our fine-tuned embedding model started showing other brands’ toasters after showing all the Cuisinart ones. In other words, fine-tuning helped our model add a sense of attribute importance (i.e., prioritize the product type over the brand).

The Power of Conversational Shopping With Clarity
With the power of NVIDIA’s models and software frameworks, we’ve been able to both enrich the product catalog and fine-tune our embedding models to deliver truly personalized conversations across your entire site through Clarity and Discovery. With the right datasets and an intentional approach, we have created a conversational agent that can drive meaningful business results.
To get even more detail into our Clarity architecture, watch our session from NVIDIA GTC featuring Vikas Jha, the VP of Engineering, Conversational Commerce, and Chirayu Samarth, the Software Engineering Manager, Search.
And, Clarity is only one of the agentic innovations we’re developing. To see what else we have in store, be sure to register for Innovation Fest, taking place on May 7.